2023-08-21
2023-09-03
研究者は情報過多という問題に絶えず直面している。毎日、ArXivやNature誌などで数百もの論文が公開され、これらに追いつくだけでストレスがかかる。私もその一人である。情報過多は研究者の生産性や創造性に悪影響を与え、誤情報に基づく判断ミスを増加させてしまうかもしれない。
この問題に対する解決策として、AI活用の下で様々なプラットフォームが連携した自動選定・自動要約システムが期待できそうだ。以前ズシさんらが報告したエントリーでは、ArXivからの論文情報とアブストを取得し、決まった時間にその要約内容をSlackへ送信する方法を示してくれた。これらのシステムは、研究者が最新の研究情報を効率的に吸収できるようになることからも、研究者の時間的・精神的負担の大幅な軽減に貢献すると思われる。
このポストでは、これらの自動投稿システムのワークフローを私なりにまとめ直した点と、Slackだけでなく、Springer Natureからの論文取得とAPI連携について紹介したいと思う。Springer Natureからの要約は自身で試行錯誤して修正・構築した。具体的なコードを修正しつつも大方は、ズシさん(@mechazushi)のこちらのエントリーを参考にした。このような論文選定・要約の自動化は、研究者にとって貴重なリソース節約に大きく貢献するくらいの価値があるだろうと思う。ぜひ皆さんも試してみてほしい。
この問題に対する解決策として、AI活用の下で様々なプラットフォームが連携した自動選定・自動要約システムが期待できそうだ。以前ズシさんらが報告したエントリーでは、ArXivからの論文情報とアブストを取得し、決まった時間にその要約内容をSlackへ送信する方法を示してくれた。これらのシステムは、研究者が最新の研究情報を効率的に吸収できるようになることからも、研究者の時間的・精神的負担の大幅な軽減に貢献すると思われる。
このポストでは、これらの自動投稿システムのワークフローを私なりにまとめ直した点と、Slackだけでなく、Springer Natureからの論文取得とAPI連携について紹介したいと思う。Springer Natureからの要約は自身で試行錯誤して修正・構築した。具体的なコードを修正しつつも大方は、ズシさん(@mechazushi)のこちらのエントリーを参考にした。このような論文選定・要約の自動化は、研究者にとって貴重なリソース節約に大きく貢献するくらいの価値があるだろうと思う。ぜひ皆さんも試してみてほしい。
目次
2. 自動投稿システムのワークフロー
論文要約の自動化システムの実装には2つステップがある。APIの取得、Google Cloud Platformの環境構築である。最初に、Slack、OpenAI、arXiv、およびSpringer NatureのAPIキーを取得する。SlackのAPIはチャットツールとして機能し、論文の要約を送る専用のチャンネルを作成する。OpenAIのAPIはAIモデルChatGPTの利用を可能にする。arXivとSpringer NatureのAPIは科学論文のデータベースへのアクセスを提供する。Springer Natureの取得方法に関しては、Springer Keyのページでサインアップが必要になり、少々手間がかかるかもしれない。他のAPIに関しては特に難しくないので、他のブログや各種ホームページを参考にしてほしい。
次に、Google Cloud Platform(GCP)で自動投稿システムを構築するために、Cloud Functionsを設定する。これにより、異なるAPIをミスなく連携させることができる。Cloud Functionsはサーバーレスの実行環境であり、APIの相互作用やデータ処理を自動化する。また、Pythonスクリプトとしてmain.pyコードを作成・編集する必要がある。3章に実例を記載するのでそれを参考にしてほしい。各APIと連携する仕組みと実際に取得したいプロンプトを所望の目的に合わせて実装するだけである。これらのプラットフォームを組み合わせることで、ChatGPTベースの論文要約システムが構築される。
このシステムの利点は数多く存在する。第一に、論文要約が自動で送信されるため、研究者の選択の手間が省かれる。第二に、要約は短くてわかりやすいため、研究者は理解の時間を節約できる。第三に、このシステムは研究の背景や関連性を迅速に把握する手段として有用である。また、Slackを用いることで、研究者同士のコミュニケーションも促進されることも期待される。一方で、このシステムには生成AIの黎明期であるが故の欠点もある。要約はAIによって生成されるため、必ずしも100%信頼できるわけではない。しかし、このあたりは時間が解決してくれると思っている。また、論文精読するためには、本文や図表の理解が必須であるため、要約だけで完全な理解をするのは難しい。
次に、Google Cloud Platform(GCP)で自動投稿システムを構築するために、Cloud Functionsを設定する。これにより、異なるAPIをミスなく連携させることができる。Cloud Functionsはサーバーレスの実行環境であり、APIの相互作用やデータ処理を自動化する。また、Pythonスクリプトとしてmain.pyコードを作成・編集する必要がある。3章に実例を記載するのでそれを参考にしてほしい。各APIと連携する仕組みと実際に取得したいプロンプトを所望の目的に合わせて実装するだけである。これらのプラットフォームを組み合わせることで、ChatGPTベースの論文要約システムが構築される。
このシステムの利点は数多く存在する。第一に、論文要約が自動で送信されるため、研究者の選択の手間が省かれる。第二に、要約は短くてわかりやすいため、研究者は理解の時間を節約できる。第三に、このシステムは研究の背景や関連性を迅速に把握する手段として有用である。また、Slackを用いることで、研究者同士のコミュニケーションも促進されることも期待される。一方で、このシステムには生成AIの黎明期であるが故の欠点もある。要約はAIによって生成されるため、必ずしも100%信頼できるわけではない。しかし、このあたりは時間が解決してくれると思っている。また、論文精読するためには、本文や図表の理解が必須であるため、要約だけで完全な理解をするのは難しい。
3. Google Cloud Platformでの環境設定
Google Cloud Platform(GCP)は、Googleによって提供されるクラウドコンピューティングサービスの一つで、ビジネスや個々の開発者が仮想マシン、データベース、ストレージ、ネットワーキング、機械学習、分析など、さまざまなサービスと機能を利用できるプラットフォームである。Google Cloud Platform(GCP)の使い方に関しては以下のとおりである。
1. GCPアカウントを作成する:Google Cloud Platformにアクセスして、アカウントを作成する。
2. プロジェクトを作成する:GCPコンソールにログインし、新しいプロジェクトを作成する。
3. Cloud Functions APIを有効化する:ナビゲーションメニューから「API & Services」へ移動し、Cloud Functions APIを有効化する。
4. 課金設定を行う:課金設定を完了し、必要な支払い情報を登録する。
5. Cloud Functionsへ移動する:ナビゲーションメニューから「Cloud Functions」を選択する。
6. 新しい関数を作成する:「Create Function」ボタンをクリックして新しい関数を作成する。
7. 関数設定を行う:関数名、メモリ割り当て、トリガー設定など、必要な設定を行う。
8. コードをアップロードする:ローカルマシンからソースコードをアップロードするか、GCP内のリポジトリからソースコードを選択する。
9. 関数をデプロイする:すべての設定が完了したら、「Deploy」ボタンをクリックして関数をデプロイする。
10. 関数をテストする:関数がデプロイされたら、GCPコンソールのテスト機能を使用して動作を確認する。
必要に応じて、環境変数の設定、ネットワーク設定、タイムアウト設定など、より詳細なオプションを調整することが可能である。
1. GCPアカウントを作成する:Google Cloud Platformにアクセスして、アカウントを作成する。
2. プロジェクトを作成する:GCPコンソールにログインし、新しいプロジェクトを作成する。
3. Cloud Functions APIを有効化する:ナビゲーションメニューから「API & Services」へ移動し、Cloud Functions APIを有効化する。
4. 課金設定を行う:課金設定を完了し、必要な支払い情報を登録する。
5. Cloud Functionsへ移動する:ナビゲーションメニューから「Cloud Functions」を選択する。
6. 新しい関数を作成する:「Create Function」ボタンをクリックして新しい関数を作成する。
7. 関数設定を行う:関数名、メモリ割り当て、トリガー設定など、必要な設定を行う。
8. コードをアップロードする:ローカルマシンからソースコードをアップロードするか、GCP内のリポジトリからソースコードを選択する。
9. 関数をデプロイする:すべての設定が完了したら、「Deploy」ボタンをクリックして関数をデプロイする。
10. 関数をテストする:関数がデプロイされたら、GCPコンソールのテスト機能を使用して動作を確認する。
必要に応じて、環境変数の設定、ネットワーク設定、タイムアウト設定など、より詳細なオプションを調整することが可能である。
4. Pythonコードの設定
Pythonスクリプトについて、具体的なmain.pyの一例を以下に示す。ここでは、Springer Natureから論文情報を取得するコードと、Arxivから論文情報を取得するためのコードを参考に見てほしい。Cloud Functionsはサーバーレスの実行環境であり、基本的なPythonコードがそのまま動くため、環境構築が短時間で完了する。さらに、Cloud Schedulerを用いて定期的な作業を自動化することができる。これにより、特定の時間にSlackに論文の要約を投稿するなどの予約投稿が可能になる。
arXive用のmain.py
import os
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
import arxiv
import openai
import random
openai.api_key = 'sk-xxxx'
SLACK_API_TOKEN = 'xoxb-xxx-xxxx'
SLACK_CHANNEL = "#paper-gpt"
def get_summary(result):
system = """
You are a science writer. I will provide you with the abstract of a research paper.
Your task is to create a title based on the abstract and write a summary in three sentences.
After that, identify seven specialized terms relevant to the core concept of the paper and provide a detailed explanation of each term, supported by scientific articles, reviews, and technical reports.LANG:jp
Furthermore, please review the paper's challenges that have yet to be achieved in this research and develop a research plan for the next steps clearly, concretely and concisely.
Finally, please provide one example of a similar study that has gained attention in recent years and is closely related to the research field of this study without any references.
All written language should be Japanese. Lang="ja_JP.UTF-8"
◆題目: \n
◆要旨: \n
◆用語: \n
1. term1
2. term2
3. term3
4. term4
5. term5 \n
◆展望:
◆類似研究:
Lang="ja_JP.UTF-8"
"""
text = f"title: {result.title}\nbody: {result.summary}"
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{'role': 'system', 'content': system},
{'role': 'user', 'content': text}
],
temperature=0.1,
)
summary = response['choices'][0]['message']['content']
title_en = result.title
title, *body = summary.split('\n')
body = '\n'.join(body)
date_str = result.published.strftime("%Y-%m-%d %H:%M:%S")
message = f"発行日: {date_str}\n{result.entry_id}\n{title_en}\n{title}\n{body}\n"
return message
def main(event, context):
client = WebClient(token=SLACK_API_TOKEN)
query ='all:(magnet AND material) OR all:(material AND learning)'
search = arxiv.Search(
query=query,
max_results=50,
sort_by=arxiv.SortCriterion.SubmittedDate,
sort_order=arxiv.SortOrder.Descending,
)
result_list = []
for result in search.results():
result_list.append(result)
num_papers = 1
results = random.sample(result_list, k=num_papers)
for i,result in enumerate(results):
try:
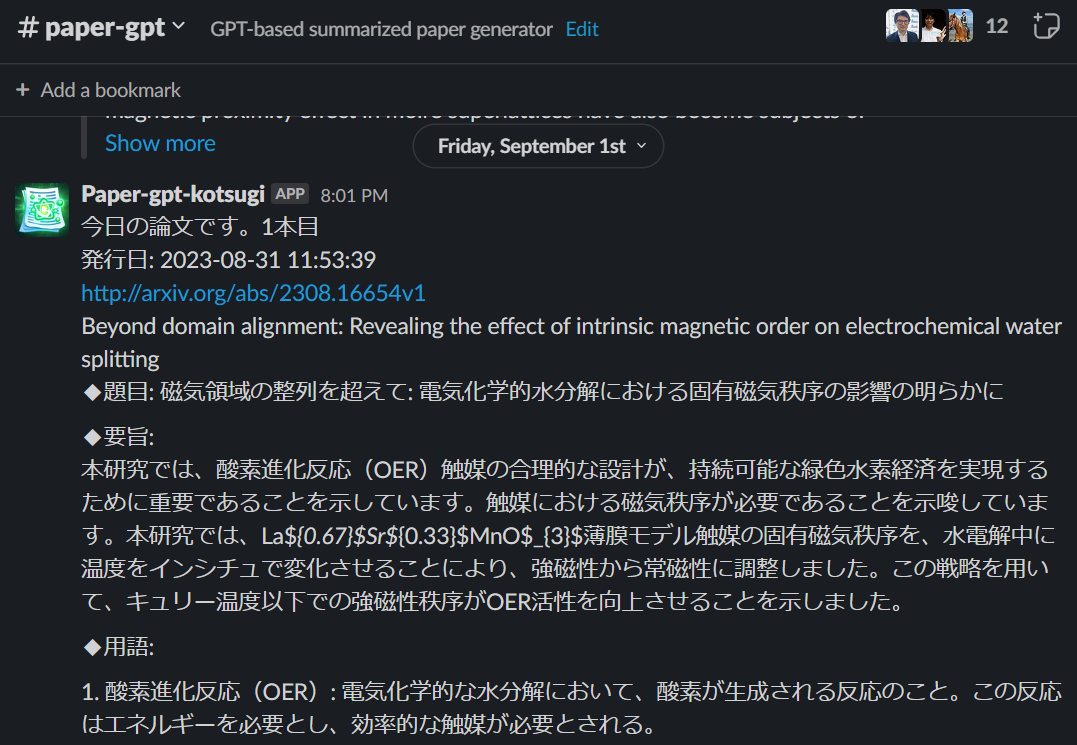
message = "今日の論文です。" + str(i+1) + "本目\n" + get_summary(result)
response = client.chat_postMessage(
channel=SLACK_CHANNEL,
text=message
)
print(f"Message posted: {response['ts']}")
except SlackApiError as e:
print(f"Error posting message: {e}")
Springer Nature用のmain.py
import os
import json
import random
import requests
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
import openai
from datetime import datetime
OPENAI_API_KEY = 'sk-xxxx'
SLACK_API_TOKEN = 'xoxb-xxxx-xxxx'
SLACK_CHANNEL = "#nature-gpt"
NATURE_API_KEY = '0abxxxx'
openai.api_key = OPENAI_API_KEY
client = WebClient(token=SLACK_API_TOKEN)
SPRINGER_API_URL = "http://api.springernature.com/meta/v2/json"
def get_summary(result):
system = """
You are a science writer. I will provide you with the abstract of a research paper.
Your task is to create a title based on the abstract and write a summary in three sentences.
After that, identify seven specialized terms relevant to the core concept of the paper and provide a detailed explanation of each term, supported by scientific articles, reviews, and technical reports.LANG:jp
Furthermore, please review the paper's challenges that have yet to be achieved in this research and develop a research plan for the next steps clearly, concretely and concisely.
Finally, please provide one example of a similar study that has gained attention in recent years and is closely related to the research field of this study (No need to add the references).
All written language should be Japanese. Lang="ja_JP.UTF-8"
◆題目: \n
◆要旨: \n
◆用語: \n
1. term1
2. term2
3. term3
4. term4
5. term5 \n
◆展望:
◆類似研究:
Lang="ja_JP.UTF-8"
"""
text = f"title: {result['title']}\nbody: {result['abstract']}"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system},
{"role": "user", "content": text}
],
temperature=0.25,
)
summary = response['choices'][0]['message']['content']
return summary
def main(event, context):
print("Function started.")
# 特定の雑誌と期間を指定する検索クエリ
query = "journal:npj Computational Materials"
params = {
"q": query,
"p": 50,
"s": 1,
"api_key": NATURE_API_KEY
}
response = requests.get(SPRINGER_API_URL, params=params)
print("Received response from Springer API.")
data = response.json()
results = data["records"]
num_papers = 1
selected_results = random.sample(results, k=num_papers)
for i, result in enumerate(selected_results):
print(f"Processing paper {i + 1}.")
try:
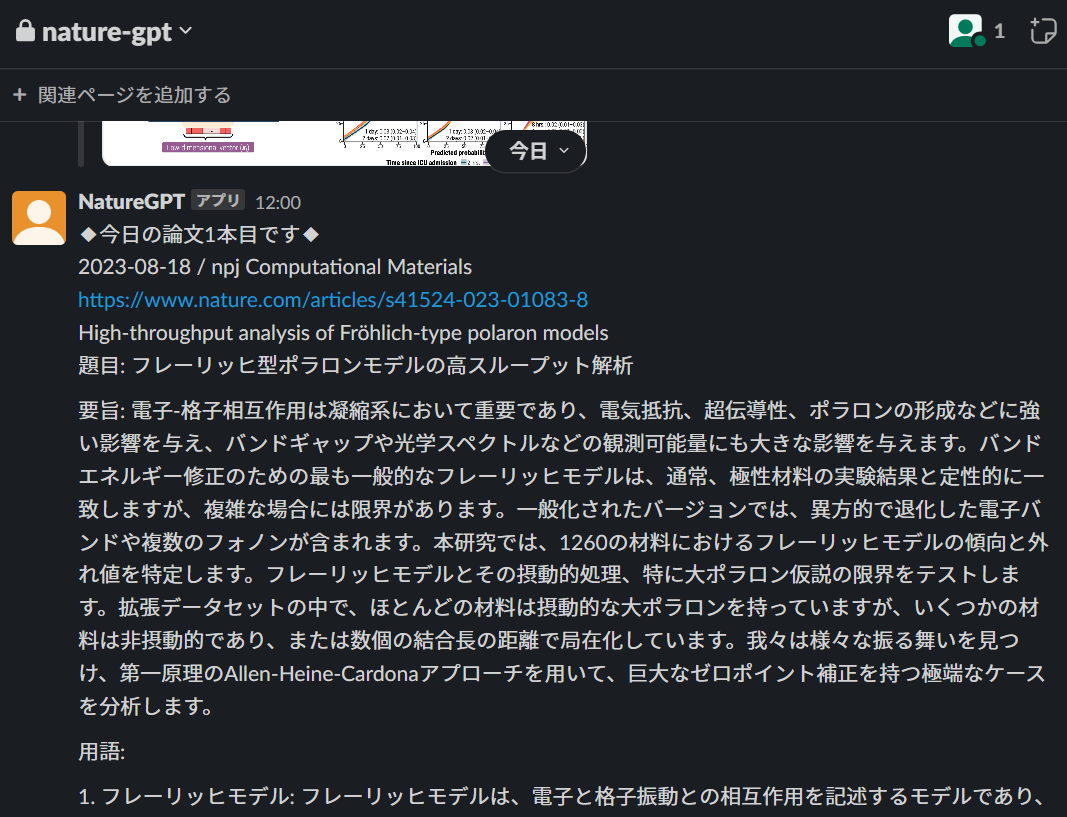
summary = get_summary(result)
message = f"◆今日の論文{i + 1}本目です◆\n{result['publicationDate']} / {result['publicationName']}\n{result['url'][0]['value']}\n{result['title']}\n{summary}"
slack_response = client.chat_postMessage(
channel=SLACK_CHANNEL,
text=message
)
print(f"Message posted: {slack_response['ts']}")
except SlackApiError as e:
print(f"Error posting message: {e}")
GCPの利点は、サーバーのメンテナンスやスケーリングを気にする必要がない点である。Compute Engineを使用する場合、これらの要素も手動で管理する必要が出てくる。しかしCloud Functionsは自動でスケーリングし、リクエストに応じてリソースを割り当てる。このため、初めてクラウド環境を使う人でも手軽に始められる。ただし、Cloud Functionsは短時間の処理に適しているため、長時間にわたる処理を必要とする場合はCompute Engineの方が適している可能性がある。この辺のトレードオフは、利用目的に応じて検討するべきだ。Cloud Schedulerについても触れておくと、これは単なるタイマーではなく、HTTPリクエストやPub/Subメッセージなどもスケジュールできる強力なツールである。例えば、毎朝9時に論文の新着情報をSlackに送るよう設定可能で、これにより研究者は新しい知識を日々効率よく取り入れられる。
5. 自動要約botの使い方
一度GCPでのトリガーが正確に動作すると、Slackでの通知は選択したチャンネルや定時で届く。通知は論文のタイトル、その要約、そして関連するキーワードと共に送られる。これにより、ユーザーはリアルタイムで最新の研究を追跡できる。要約メッセージ内に設置したキーワード解説も非常に有用である。特に、新しい研究領域に挑戦するケースや複数の分野にまたがる研究を行っている人にとって大事である。例えば、物性物理の研究者が突然「データサイエンス」に興味を持った場合、要約やキーワード解説で速やかに基本概念を掴むことができる。更に、今後の展望や関連研究の表示等を表示することで、その分野への理解も深化させることができる。このような特長により、このSlackベースのシステムは、情報過多の時代において、効率的かつ直感的に最新の研究にアクセスできる方法を提供する。つまり、このシステムはただの情報通知ツール以上の価値がある。
このシステムの最大の利点は時間の節約にある。手動で論文を探し、読んで要約するプロセスが自動化されることで、研究者は他の重要な作業に集中できる。具体的には、週に5本の論文を読むと仮定して、各論文に平均3時間かかる場合、週に15時間もの時間を節約できる。この時間は新しい研究に投資できる貴重なリソースとなる。さらに、キーワード解説機能によって研究の幅も広がる。特定の分野に狭く固執することなく、多様なテーマに対する洞察も可能になり、研究者特有の視野の狭さ問題も緩和される。
一方で、このシステムも完璧ではない。自動生成される要約は、研究の複雑性や新規性によっては不完全または誤解を招く場合がある。特に数式や専門的な実験手法が多用された論文に対しては、自動要約の品質が低下する可能性がある。さらに、APIの使用料やSlackの通知制限も考慮すべき課題だ。ただし、現状毎日3本送るように設定しており、100本弱の要約生成に先月は36円という破格である。個人利用では全く問題がないといえる。途中から学習モデルをGPT-3.5-turboからGPT-4に変更したが、金額はほとんど同じであった。もちろん、大規模な研究チームでの利用や大量のデータ取得には、予想以上のコストがかかる可能性もある。私も設定をいじりすぎたために、2000円程度まで到達した月もあった。また、APIの利用には規約があり、それに違反すると問題が発生する可能性があるという注意が必要である。
このように総合的に見れば、このシステムは時間とリソースを効率的に使う強力なツールであるが、その制限とコストも理解して活用する必要がある。特に研究の深掘りが必要な場合や、コスト面での制約がある場合は、システムの活用方法を工夫するか、補完的な手段を考慮する必要がある。
このシステムの最大の利点は時間の節約にある。手動で論文を探し、読んで要約するプロセスが自動化されることで、研究者は他の重要な作業に集中できる。具体的には、週に5本の論文を読むと仮定して、各論文に平均3時間かかる場合、週に15時間もの時間を節約できる。この時間は新しい研究に投資できる貴重なリソースとなる。さらに、キーワード解説機能によって研究の幅も広がる。特定の分野に狭く固執することなく、多様なテーマに対する洞察も可能になり、研究者特有の視野の狭さ問題も緩和される。
一方で、このシステムも完璧ではない。自動生成される要約は、研究の複雑性や新規性によっては不完全または誤解を招く場合がある。特に数式や専門的な実験手法が多用された論文に対しては、自動要約の品質が低下する可能性がある。さらに、APIの使用料やSlackの通知制限も考慮すべき課題だ。ただし、現状毎日3本送るように設定しており、100本弱の要約生成に先月は36円という破格である。個人利用では全く問題がないといえる。途中から学習モデルをGPT-3.5-turboからGPT-4に変更したが、金額はほとんど同じであった。もちろん、大規模な研究チームでの利用や大量のデータ取得には、予想以上のコストがかかる可能性もある。私も設定をいじりすぎたために、2000円程度まで到達した月もあった。また、APIの利用には規約があり、それに違反すると問題が発生する可能性があるという注意が必要である。
このように総合的に見れば、このシステムは時間とリソースを効率的に使う強力なツールであるが、その制限とコストも理解して活用する必要がある。特に研究の深掘りが必要な場合や、コスト面での制約がある場合は、システムの活用方法を工夫するか、補完的な手段を考慮する必要がある。
6. おわりに
AIと自然言語処理技術は進化しており、ChatGPTを用いた多方面での応用が可能となっている。本システムも今後、データベース連携や多言語対応を進め、研究者の多様なニーズに応える方向に進化することが期待される。特に、物性物理や材料科学のような専門領域では、新しい材料や性質の探索が重要な研究課題であり、このシステムの応用はそのような領域でも高い潜在能力を持っている。本ブログで紹介したようなシステムの更なる発展と適用は、情報過多という課題に対処し、高効率な論文選別や研究提案を実現する手段として、今後ますます重要になると考えられる。
参考リンク
- ズシさん(@mechazushi)のエントリー: zenn.dev/ozushi/articles/ebe3f47bf50a86
- Slack api: api.slack.com/apps
- OpenAI APIs: platform.openai.com/account/api-keys
- Springer Nature API portal: dev.springernature.com/
- arXiv api: info.arxiv.org/help/api/basics.html
- Google Cloud Platform: cloud.google.com/